Mehrphasen-Reaktionstechnik
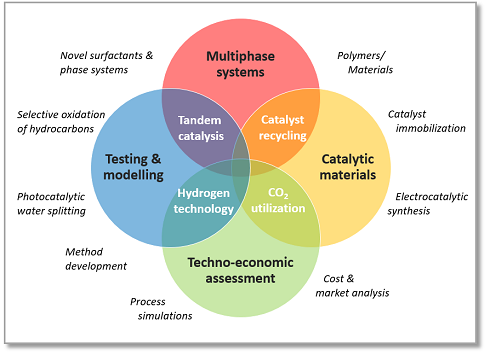
In unserem Arbeitskreis werden Untersuchungen im Bereich der Homogenen- und Heterogenen Katalyse durchgeführt. Dabei gilt es Reaktionsbedingungen zu finden unter denen Reaktionen nachhaltig und effizient durchgeführt werden können. Dies schließt sowohl Katalysatorsynthese, kinetische Untersuchungen als auch Modellierungen zur Ermittlung eines entsprechenden kinetischen Ansatzes mit ein.